You’ve likely experienced this: you’re having an incredible conversation with an LLM (like GPT-4 or Claude), building up complex context, only to open a new tab the next day... and the AI has no idea who you are. Or worse: within the same conversation, it starts forgetting instructions given just 50 messages ago.
The industry has tried to solve this with brute force: "Increase the context window!". We’ve gone from 4k tokens to 128k, 1 million, 10 million. But this creates two major new problems:
- Prohibitive Cost: Sending an entire book of context with every prompt costs a fortune in processing.
- Noise ("Lost in the Middle"): The model gets lost when trying to find a needle in a haystack of irrelevant information.
The truth is: Context is not Memory. Your brain doesn't work by keeping everything you saw last week "active" in working memory. It selects, summarizes, and consolidates what is important, discarding the rest.
It was with this in mind that I developed and published DREAM (Dynamic Retention Episodic Architecture for Memory), an architecture designed to give AIs long-term memory that is economically viable, technically scalable, and privacy-focused.
What is DREAM?
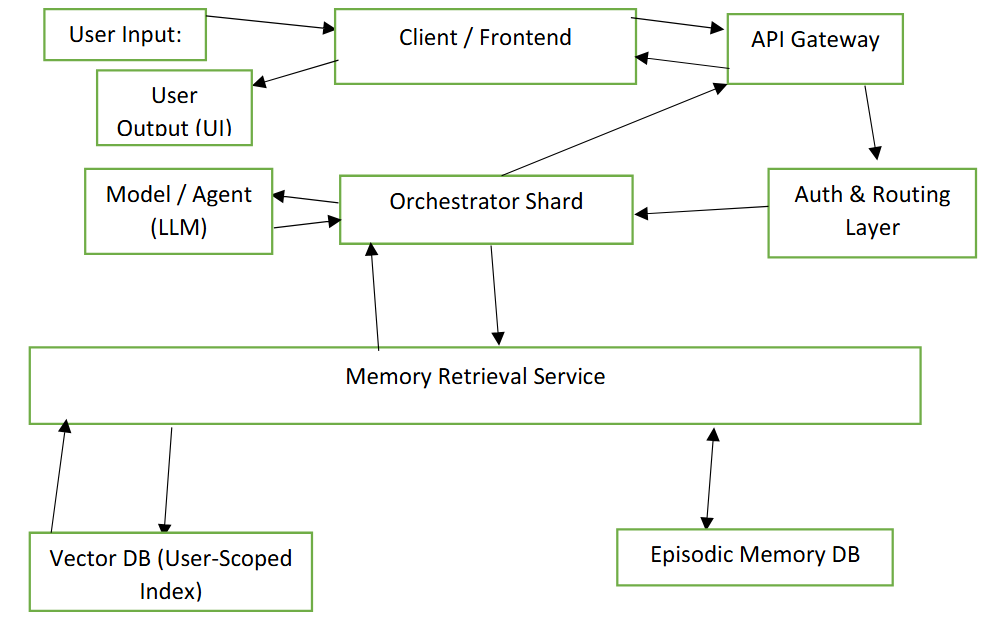
DREAM is not a new AI model. It is a system architecture that wraps around the LLM. It acts as an "Artificial Hippocampus," managing the lifecycle of user memories.
The architecture was designed to be model-agnostic (working with OpenAI, Anthropic, Llama) and uses standard market infrastructure (Vector Databases, NoSQL, Kubernetes), making it implementable today, not in a distant future.
Here are the pillars that make DREAM different from simple RAG (Retrieval-Augmented Generation):
1. Episodic Memory, Not Chat Logs
Most systems try to save the raw chat history. This is inefficient. DREAM introduces the concept of Episodic Units (EUs).
Instead of saving raw text, the system runs a background process that generates a compressed summary of the interaction, extracts metadata (topic, emotion), and generates a vector embedding. This transforms gigabytes of text into kilobytes of structured, semantically rich memory.
2. The Adaptive Retention Mechanism (ARM)
This is the central innovation. How do we prevent the database from growing infinitely with garbage?
Inspired by biological memory consolidation, DREAM uses a Dynamic TTL (Time-To-Live). It works like this:
- When a memory is created, it has a short life (e.g., 7 days).
- If you never touch that subject again, the memory expires and is automatically deleted ("Active Forgetting").
- If the system needs to retrieve that memory to answer a new question, the TTL is extended, doubling in value (7 days to 14 days to 28 days...).
This creates a self-pruning database. The system "forgets" the trivial and "remembers" forever what is recurrent and important to the user.
3. Dual Output Mechanism
To ensure performance, DREAM proposes a flow where the LLM generates two simultaneous outputs:
- The response for the user (in the interface).
- An internal "memory candidate".
This allows for the implementation of User-Centric Opt-In. The system can ask (or infer via policy): "Should I remember this?". If the user says no, the data dies there. This solves privacy and GDPR issues by design.
4. Scalability via Sharding
Unlike academic prototypes that run on a single machine, DREAM was designed to scale to millions of users. It uses Orchestrator Sharding, where users are deterministically distributed across processing nodes.
A user's episodic memory and vector index live on the same physical node that processes their requests, ensuring ultra-low latency in context retrieval.
Why does this matter?
We are moving from the era of "Chatbots" to the era of "Agents and Cognitive Partners." A partner needs to remember who you are, what your goals are, and what you discussed last week.
DREAM offers a blueprint for building this persistence layer without breaking the bank with storage costs or slowing down inference with massive contexts.
Read the Full Paper
I have published the full architecture specification, including the TTL calculation algorithms, data flow diagrams, and implementation analysis, as an open-access preprint.
If you are a developer, researcher, or software architect, I invite you to read the original document and implement these concepts in your projects.
📄 Access the DREAM Paper on Zenodo: https://zenodo.org/records/17619917